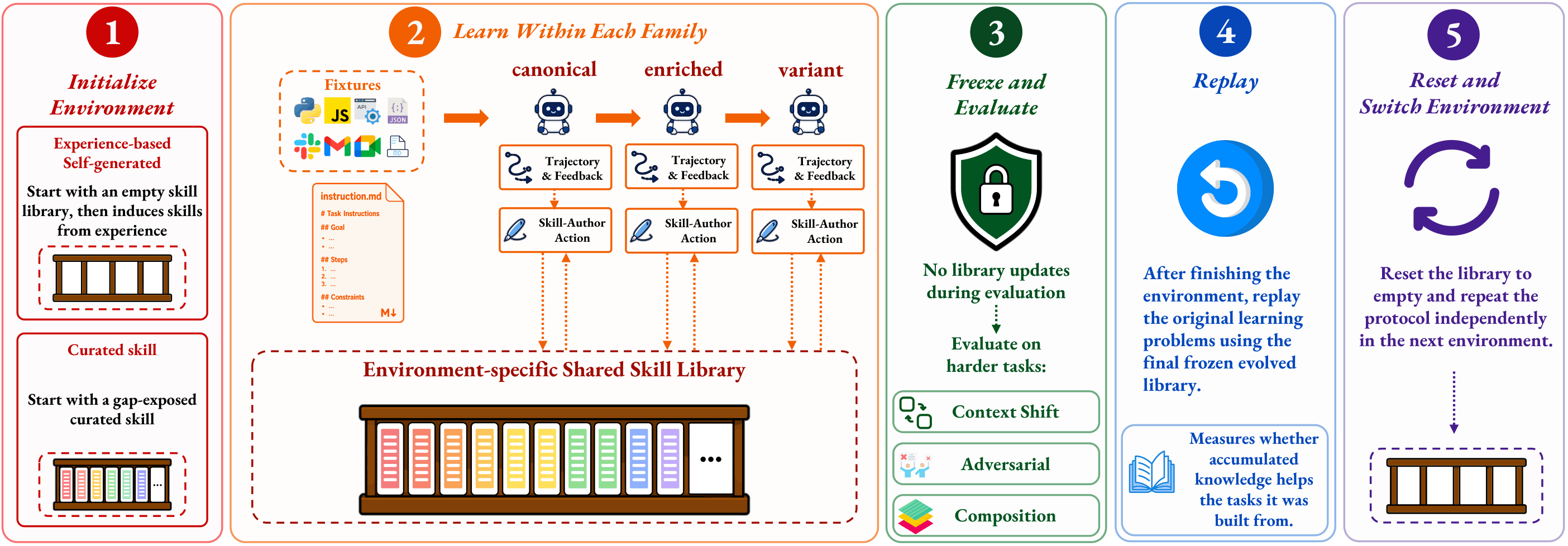
Acquisition uses the canonical, enriched, and variant roles. All acquisition tasks in an environment are completed before deployment begins. The active library is scoped to the environment: skills learned from earlier families may be visible to later families in the same environment, but skills never transfer across environments. Each acquisition attempt yields a compacted trajectory summary from harness-recorded artifacts such as instructions, file accesses, tool calls, commands, edits, generated outputs, tests, and final responses; verifier feedback includes outcome results, process checks, rewards, and diagnostics.
Skill authoring is family-local. Although the task-solving agent may read the environment-level library, the Skill Author receives only same-family skills and same-family acquisition history. After acquisition, the library is frozen: deployment tasks may read and apply accumulated skills but may not create, revise, retire, or otherwise modify them. Replay then reruns the original acquisition tasks using the final frozen library, providing a within-environment counterfactual for whether accumulated knowledge helps the tasks it was built from.
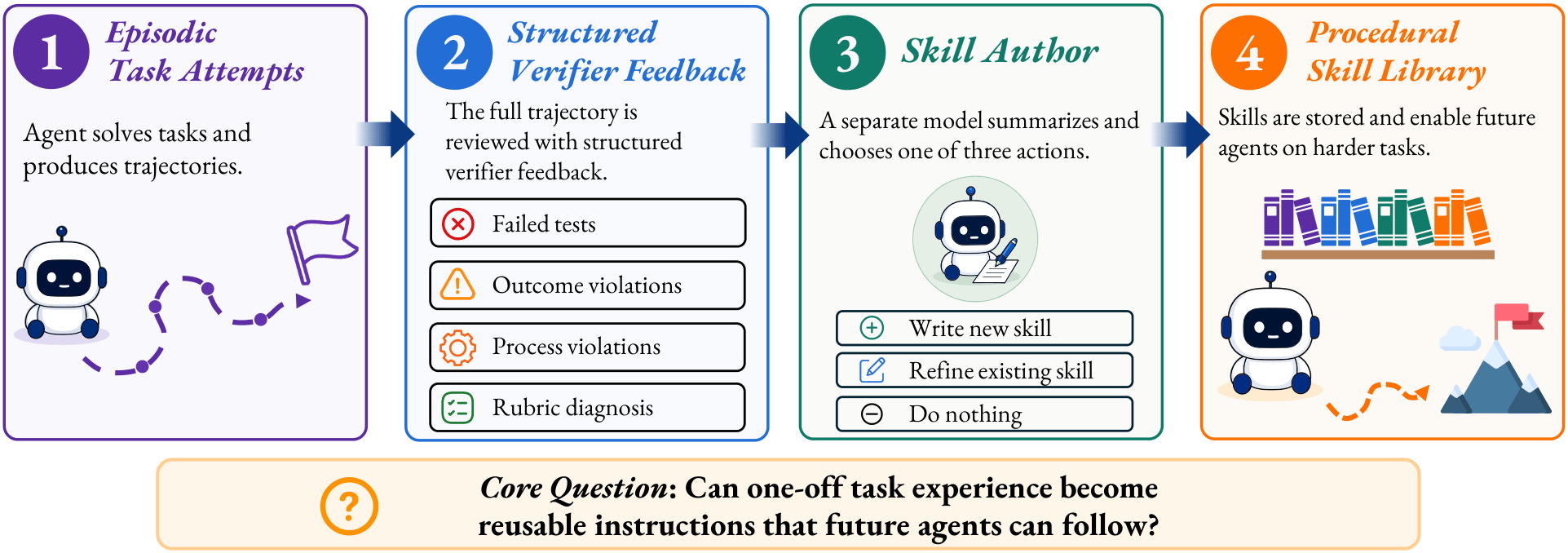
Acquisition creates evidence
Canonical, enriched, and variant tasks produce compacted execution artifacts and verifier feedback for possible skill updates.
Skill updates are externalized
A separated Skill Author updates an environment-scoped library, making the learned procedure inspectable and reusable.
Deployment is frozen
Context-shift, adversarial, and composition tasks test transfer without further updates; replay isolates local recovery.